Devpost
Participate in our public hackathons
Devpost for Teams
Access your company's private hackathons
Grow your developer ecosystem and promote your platform
Drive innovation, collaboration, and retention within your organization
By use case
Blog
Insights into hackathon planning and participation
Customer stories
Inspiration from peers and other industry leaders
Planning guides
Best practices for planning online and in-person hackathons
Webinars & events
Upcoming events and on-demand recordings
Help desk
Common questions and support documentation
A test-time-adaptive compiler that burns a tiny neural network onto a real FPGA, using synthesis/simulation feedback to improve the hardware config for that exact model and board.
pushing on-device inference beyond its limits
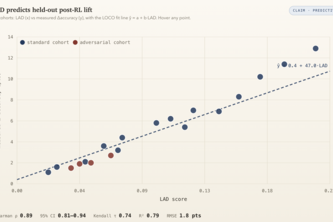
LAD predicts whether RL data will improve a model before costly training, using only a few rollouts per task, no gradients, to deliver cheap, accurate lift forecasts where costly proxies fall short.
Spend compute to climb to correct.
Text-based memory is inefficient and wastes context. We use hypernetworks (Doc-to-LoRA) to allow agents to edit their own parameters at inference time, applied to memory, personalization, and skills.
DistEvaL is an evaluation framework for AI agents that automatically identifies where an agent is inconsistent, and turns those inconsistencies into usable training data that helps re-train the agent.
self-customizing personal companion directly in your browser and mobile.
Organizing physical human intelligence.
Sandra is an AI agent for bioinformatics, automating folding, sequence analysis, and research pipelines so scientists go from question to result in minutes, not weeks :)
Start thousands of parallel agents in under 500ms. sui clones any git repository in under 1 second and creates worktrees in 100ms
Breaking Online-Softmax Dependencies for Long-Context Decode
Financial Superintelligence
cheaper RL through reasoning trace distillation
Metagradients for data filtering. Optimized w/ TK kernels & distilled metagrad-approximator model.
The future of compute is shared latent state. Our demo shows what happens when bandwidth carries meaning instead of pixels, and edge devices stop wasting silicon on duplicated work.
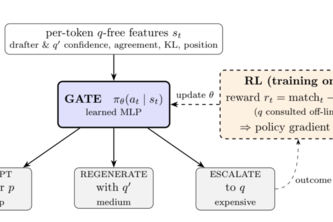
S4D is a state-of-the-art hierarchical speculative decoding method that replaces hand-tuned speculative-decoding thresholds with a learned per-token routing policy
Adaptive AI red-teamer agent that poisons a coding agent's context to surface unsafe-merge vulnerabilities, scored by an LLM judge.
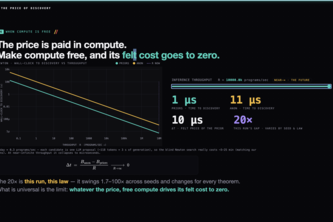
With infinite compute, what is knowledge worth? We measured it: stripped of semantic clues, an LLM needs ~12–20× more inference to rediscover natural law—a price that falls to zero as compute scales.
Extreme compression of transformers - diffusion models, LLMs, etc Compressed Sana-1.6B diffusion model from 3.2GB to 0.5GB with little loss in quality!
Komachi AI combines your health records, local real-world data, and global medical evidence to provide personalized guidance for safer alcohol consumption decisions that protect your future health.
A self-improving predictor that tells you if RL data will improve your model, without needing to actually train.
An interactive book-to-video platform - highlight any passage and get a cinematic clip that's true to the story.
Turn your world model interactive without training.
1 – 24 of 46